
与传统方法相比,检测性能提升16%−33%,与最先进的深度学习算法相比,成本降低33%,最重要的是它经过大规模实车数据集的验证,具备极强的实际应用价值,它就是来自昇科能源的电池异常检测深度学习模型。
9月23日,昇科能源携手清华大学欧阳明高院士团队和北大科研团队的最新研究成果《动态深度学习实现锂离子电池异常检测》(《Realistic Battery Fault Detection with Dynamical Deep Learning》)正式在Nature子刊《Nature Communications》刊出,它面向实际数据的锂离子电池安全预警问题,搭建了基于动态变分自编码器的电池异常检测深度学习框架(dynamical autoencoder for anomaly detection, DyAD),并通过实际社会经济影响因子分析优化深度学习模型,实现高检出率、低误报率的电池异常检测,同时发布了包含347辆电动汽车的69万条充电片段的大规模实车电池数据集。
电动汽车电池的故障预测可以节省社会成本并推动EV的普及,但由于电池系统是高度复杂的非线性系统,相关研究在实际应用中还有很长的路要走。原因有两个:
第一,现有算法的验证仅在小规模实验室环境中进行,算法需要进一步测试;
第二,现有的很多算法依赖于在现实世界环境中不可用的信息,无法顾及数据可用性、经济性、传感器噪声和模型隐私等因素,无法应用于实际场景。
昇科能源携手清华大学欧阳明高院士团队和北大科研团队开发了一种名为DyAD的深度学习模型,能更有效地预测锂离子电池异常,同时显著降低成本,提高实用性。
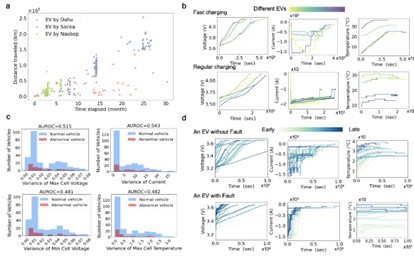
图1 发布的大规模实车电池数据集
动态变分自编码器提取大规模实车电池异常数据
发布的大规模实车电池数据集如图1所示,来源于三家制造商,存在快充慢充等不同充电工况,数据样本多样且不规则,通过简单的电压、电流、温度变化、充电曲线对比等手段无法区分正常车辆和异常车辆,因此,利用动态变分自编码器对如此大规模的实车电池数据蕴含异常信息进行特征提取。
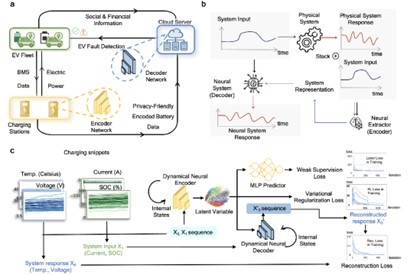
图2 基于动态变分自编码器的电池异常检测深度学习框架
DyAD深度学习模型对电池特征进行动态编译和解译
文章提出的深度学习架构如图2所示,该模型架构可直接部署于实际场景的充电站、电动汽车以及云端服务器(图2a),充电站收集BMS数据并进行编译以保护用户隐私,进而上传至云端服务器,实现云端独立的电池异常检测结果输出,同时还考虑了异常检测引起的社会经济效益并进行经济性最优检测分析。
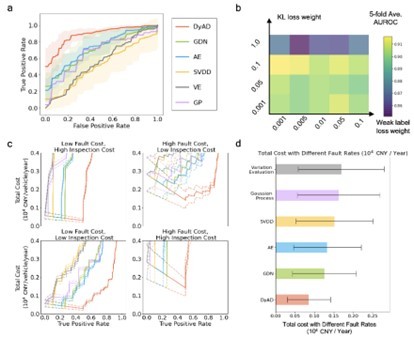
图3 实车电池数据集的检测结果及经济性分析
DyAD深度学习模型检测性能提升16%−33%,成本降低33%
DyAD深度学习架构对大规模实车电池数据集的检测结果及经济性如图3所示。文章将DyAD模型与现有几种常见深度学习算法进行比较,分别是graph deviation network(GDN), vanilla autoencoder (AE), support vector data description (SVDD), Gaussian process model (GP),以及一种统计数据驱动电池检测算法 (variation evaluation, VE),并用受试者工作特征曲线面积(Area Under the Receiver Operating Characteristic Curve,AUROC)作为对比量化指标。实验结果表明,相比于几种常见算法,文章提出的深度学习架构可以提升16%−33%的AUROC并保持微小的性能波动(图3a)。
而在经济性方面,通过昇科能源在北京、上海等国内一线城市的车辆数据统计,对DyAD以及几种常见算法的经济性进行优化对比,得到DyAD深度学习模型在不同故障成本与检修成本情况下可平均减少33%的直接成本(图3c与图3d)。
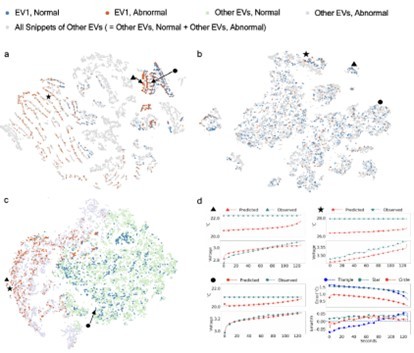
图4 异常检测算法对电池物理知识的学习原理解析
DyAD深度学习模型保证电池异常检测的高检出率、低误报率
此外,文章还对DyAD模型在实际实车数据中学习到的物理知识原理进行解析,如图4所示。研究者观察了训练过程中所有电池充电片段在提出的深度学习架构的三个代表性层级(输入层 图4a、隐藏层 图4b、输出层 图4c)之间的演化归类情况,并用t-SNE (t-distributed stochastic neighbor embedding)的可视化技术把每个充电片段映射成一个二维空间中的一个点。为了便于观察,随机挑选公开的大规模数据集中某辆车辆,并突出标注了该辆车辆的异常片段(红色点)和正常片段(蓝色点)。图4c的输出层可以清楚看到所有车辆的异常片段和正常片段被DyAD分为了两块明显区分的区域,而从图4a到图4c的演化过程中,随机挑选的某辆车辆的异常片段(红色点)和正常片段(蓝色点)也从输入层(图4a)的无序随机分布状态变化为输出层(图4c)在两块区域几乎独立分布状态。此现象表明,DyAD深度学习架构的底层训练逻辑是通过重构误差聚类实现了对电池关键物理特征信息的提取学习,从而能够保证电池异常检测的高检出率、低误报率。