7月5日,理想汽车召开了2024智能驾驶夏季发布会。在发布会上理想汽车表示,OTA 6.0.0版新增无图NOA功能,并将于7月内全量推送,覆盖的所有的AD Max车型。同时,理想汽车发布了基于端到端模型、VLM视觉语言模型的全新自动驾驶技术方案。

▍理想无图NOA到底有哪些提升?
无图NOA四大能力

理想汽车最新的无图NOA,不管是在城市、城镇,还是乡村小路,都能够行驶。最新的无图NOA相比过去的版本,BEV、感知能力、规控能力,还有整体系统能力都得到全面的提升,无图NOA摆脱了对先验信息(有图)的依赖。
1、哪里都能开,不再依赖过多“先验信息”。理想汽车的智能驾驶系统背后有很多“小机器人”在运行,可能有一些“小机器人”需要一些先验信息。但是随着感知、规控能力的提升,就不再需要先验证,能更自如地解决在道路行驶中遇到的各种各样的路况。
2、绕行丝滑,时空联合。在实际道路上驾驶,会经常遇到一些车辆、行人等对象,阻碍我们通行。这种情况下,就会“绕行丝滑”,它背后是时空联合能力,就是具备时间和空间的能力。空间概念是横纵(前后左右)同步规划,时间概念是能够持续预测自车与他车的空间交互关系,并规划出未来一段时间窗口内的所有可行驶的轨迹,筛选出最优最高效的轨迹。
3、路口轻松,上帝视角。路口轻松过背后是我们具备“上帝视角”的能力。将摄像头拼接的周边环境、道路信息、导航提供的轨迹和数据信息全部合并在一起,形成超视距能力,在通过路口的时候找到最优路线。
4、默契安心,分米级微操。无图NOA重点考虑了用户心理安全边界的设计,将纯视觉的Occ占用网络升级为Lidar与视觉前融合的占用网络,从而识别更大范围内的不规则障碍物,感知精度也会更高。提升可行驶区域内的安全性和连续性,可以做到分米级别的微操。让用户和车之间产生了一种默契和安心的感觉。
主动安全四大能力

主动安全四大能力,包括复杂路口AEB,夜间弱光AEB,全自动AES,全方位低速AEB。
复杂路口 AEB(自动紧急制动):行人、两轮车、三轮车这三种障碍物,不管是从左、右、前任何一个方向靠近时,如果它侵占了车辆的安全系统区间,车辆都会启动AEB主动刹停。同时,如果车辆侵占了对方的安全空间,车辆也会主动刹停。
夜间AEB(自动紧急制动):在高速上夜间行驶,周围基本上没有光照,前方不远处有一辆货柜车停着静止不动,没有开灯、没有反光条。在这种极限场景下,理想AD Max的AEB能做到120公里时速完全刹停。
全自动AES(自动紧急转向):场景为消失的前车,行驶过程中的我车和前车,都以非常快的速度在高速上行驶,突然前车的前车紧急刹停,前车避让而我车距离很近不可能刹停。这种情况下车辆会减速并避让过去,无需人为参与转向操作,车辆会自动紧急转向,避让前方障碍物。
全方位低速AEB(自动紧急制动):用户在日常生活的低速场景中,特别在地库停车环境复杂的情况下,可能会出现比如柱子、墩子,车辆会启动低速AEB,可以刹停,避免剐蹭。
真正实现自动驾驶的技术方案是什么样的?
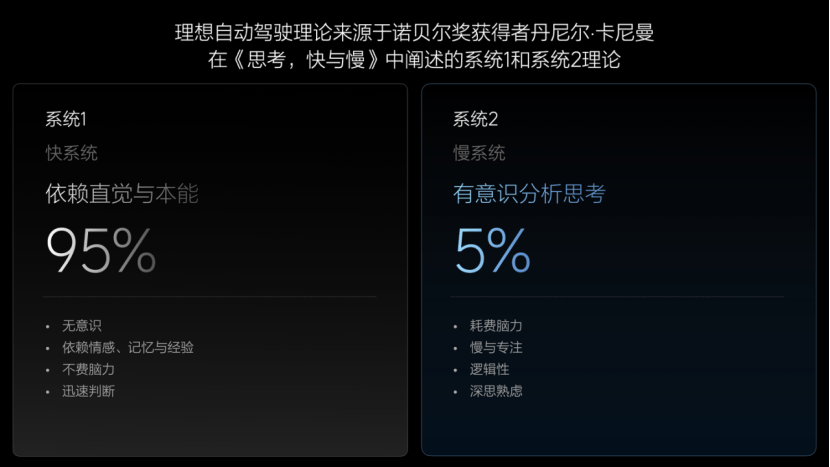
理想自动驾驶理论来源是《思考,快与慢》理论。诺贝尔经济学奖得主丹尼尔·卡尼曼在《思考,快与慢》中阐述了认知心理学中系统1与系统2的概念,为理解人类的认知模式提供了一个重要框架。
系统1其实是人根据自己过去的经验和习惯形成的直觉,可以做出快速的决策。系统2其实是一个思维推理能力,人需要经过思考或推理才能解决这种复杂的问题和应对未知的场景。简言之,系统1和系统2相互配合,成为了人类认知和理解世界、做出决策的基础。
系统1和系统2是如何应用到自动驾驶中的?
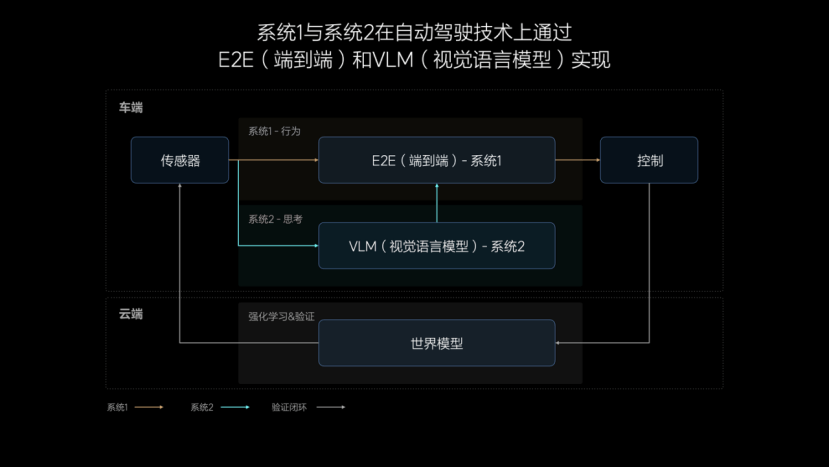
系统1由一个端到端模型(E2E)实现,直接用来快速响应常规驾驶问题。
系统2由一个视觉语言模型(VLM)实现,里面包含了思考的能力。
我们利用世界模型在云端来验证系统1和系统2的能力。
以上三个系统组成了理想汽车下一代自动驾驶技术架构。
什么是端到端,到底是哪个端到哪个端?它和以往的智能驾驶系统有什么区别?
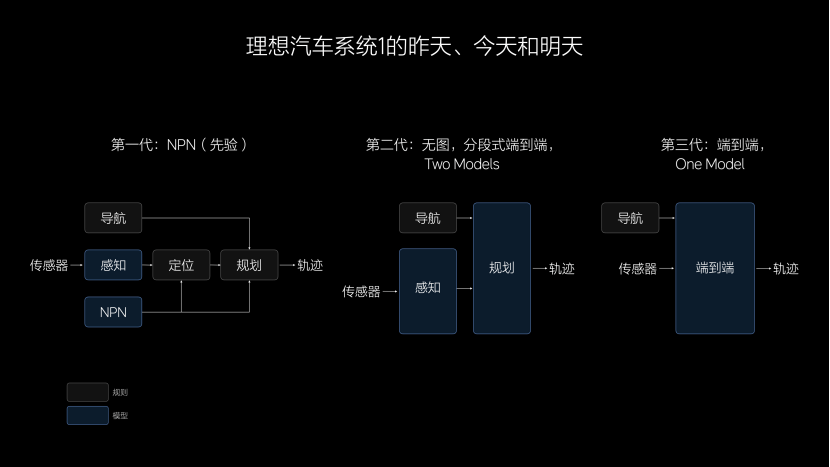
理想汽车系统1的进化过程:
第一代:NPN。采用模块化的设计,包含感知、定位、规划、导航、NPN等,这一代架构支撑我们在全国100个城市推送了城市NOA功能。
第二代:无图,分段式端到端。只有两个模型组成,分别是感知和规划。最大的变化是去掉了NPN,不依赖于先验信息,让我们真正做到了全国都能开,有导航就能开。
第三代:端到端模型,它是一个One Model的结构,只有一个模型,输入的是传感器,输出的是行驶轨迹。
端到端模型的优势在于:

1、高效传递,驾驶体验更聪明和更拟人。
在无图中有两个模型,模型之间的信息传递我们运用了大量的规则;而到了端到端模型,它是一体化的模型,信息都在模型内部传递,具有更高上限。用户所能感受到整套系统的动作、决策更加拟人。
2、高效计算,驾驶时车辆会反应更及时和更迅速。
因为是一体化模型,可以在GPU里一次完成推理,端到端的延迟会更低。用户感知到的是,眼睛和手协调一致,反应迅速,车辆动作响应及时。
3、高效迭代 ,更高频率的OTA。
一体化模型可以实现端到端的可训,完全的数据驱动。对于用户来说最大感受就是OTA的速度越来越快。
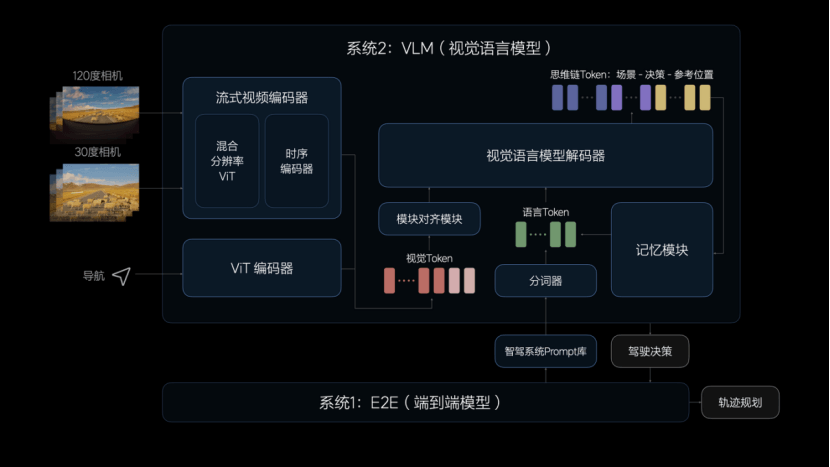
系统2:VLM(视觉语言模型)。整体算法架构是由一个统一的Transformer模型组成,将Prompt(提示词)文本进行Tokenizer(分词器)编码,然后将前视120度和30度相机的图像以及导航地图信息进行视觉信息编码,通过图文对齐模块进行模态对齐,统一交给VLM模型进行自回归推理,VLM输出的信息包括对环境的理解、驾驶决策和驾驶轨迹,并传递给系统1控制车辆。